As software developers we have a need to build good software. Due to this need, we tried to find different heuristics to build better software easier.
Since we left the punch cards and started with assembler, we started researching for tools to be more efficient and being able to understand better our code. How we used these tools together and how we applied them, became patterns, and a combination of these patterns, we started seeing paradigms.
Nowadays, we could say that there are three main paradigms on how we design software. Essentially, everything else distilles from a subset or superset of these paradigms. These paradigms are, simplifying a bit the description:
- Procedural Programming: Aims to divide a program in routines or procedures that mutate a subset of the state of the program.
- Object Oriented Programming: Aims to divide a program in objects, each with it's own state, and mutation happens through messaging between objects.
- Functional Programming: Aims to divide a program in functions that through a composition of these functions and effects, achieve an end result.
All paradigms, at least, try to solve two specific questions of software development:
- How do we handle state?
- How do we split software components?
| Paradigm | State | Modularisation |
|---|---|---|
| Procedural | Mutable shared state | Procedures that mutate a slice of the state |
| Object Oriented | Mutable isolated state | Messages that trigger changes on a slice of the state |
| Functional | Immutable shared state | Functions that are composed and invoked to build new state |
All paradigms have their trade offs: despite the typical flame war of what paradigm is better, there is no best way of doing things. No wonder why all modern languages are now multiparadigm and allow mixing tools from all paradigms to make better software.
However, the discussion is still there: is it better to do OOP? or FP? Should we just drop all of this and go back to procedural programming? Take a look at Reddit, X or even YouTube. It's just easy content with lots of engagement: who doesn't want a quick discussion about tabs vs spaces, vim or emacs or whatever?
For simple software, like a "Hello world", it doesn't matter. We can just do either way, it won't change, it will be just called by 1 user in 1 machine, it doesn't need internasionalisation, or accessibility. It doesn't need to be redundant or secure, there are no privacy concerns...
Because issues happen at scale
How we split software is essentially an accidental necessity of scale. We need to scale teams, organisations, servers, data storage... and so on and so forth. When we decide how to split things is because we need are trying to capture a problem and its solution in a formal language that needs to be useful for everyone in our team, organisation or community.
When we are working in a team, there are lots of things to consider: and let's keep us honest here. We are actually not considering all of them. When you are building your software, are you considering how we can make features parallelisable? Or faster to implement? Or safer? Are you considering how accessible it is to external contributors? Or what it would happen if we deploy the software in another country?
No, because software is situational
What do I mean by situational? That software is useful just for a set of problems. There is no good software, but good software for something. Is your software designed to be efficient? Or is it designed to be easy to change? Maybe none of them, it's designed to be easy to scale on multiple machines across different geographical regions and requires strict procedures for deploying new versions due to legal requirements.
Software Design is about boundaries and trade offs
A good software designer has to take into consideration how things evolve, devolve, fail, succeed, scale... and it is extremelly complicated to handle all of this by yourself. While it's really easy to have opinions on whether it's easier to understand two snippets of code between object oriented or functional programming, it doesn't matter in reality.
Because it's not about adding or removing lines of code, is about something more complicated: how software evolves and behaves on change. Software has to bee like pottery: when you are working with clay, you mold and shape the software while it's running. However, that software is not only changed by you, but also by other people.
So, how do we design good software?
I could tell you to follow some guidelines or really known principles that I know they work fine: be agile, do DDD, and test your software. That would be the easiest way to get out of this post, however, I don't like the easy way. What I want to do now is to give you an idea on what are some base rules and properies to define good working software.
Because good software is about expectations.
So if you manage to define your expectations and design software based on that, you have solved the easy part the problem.
Software is about how components interact and change
If you've seen how paradigms are defined, they are usually focused on how you make components interact with each other to solve problems. A good software designer is intentional when they define the boundaries between components, independently of the shape they have.
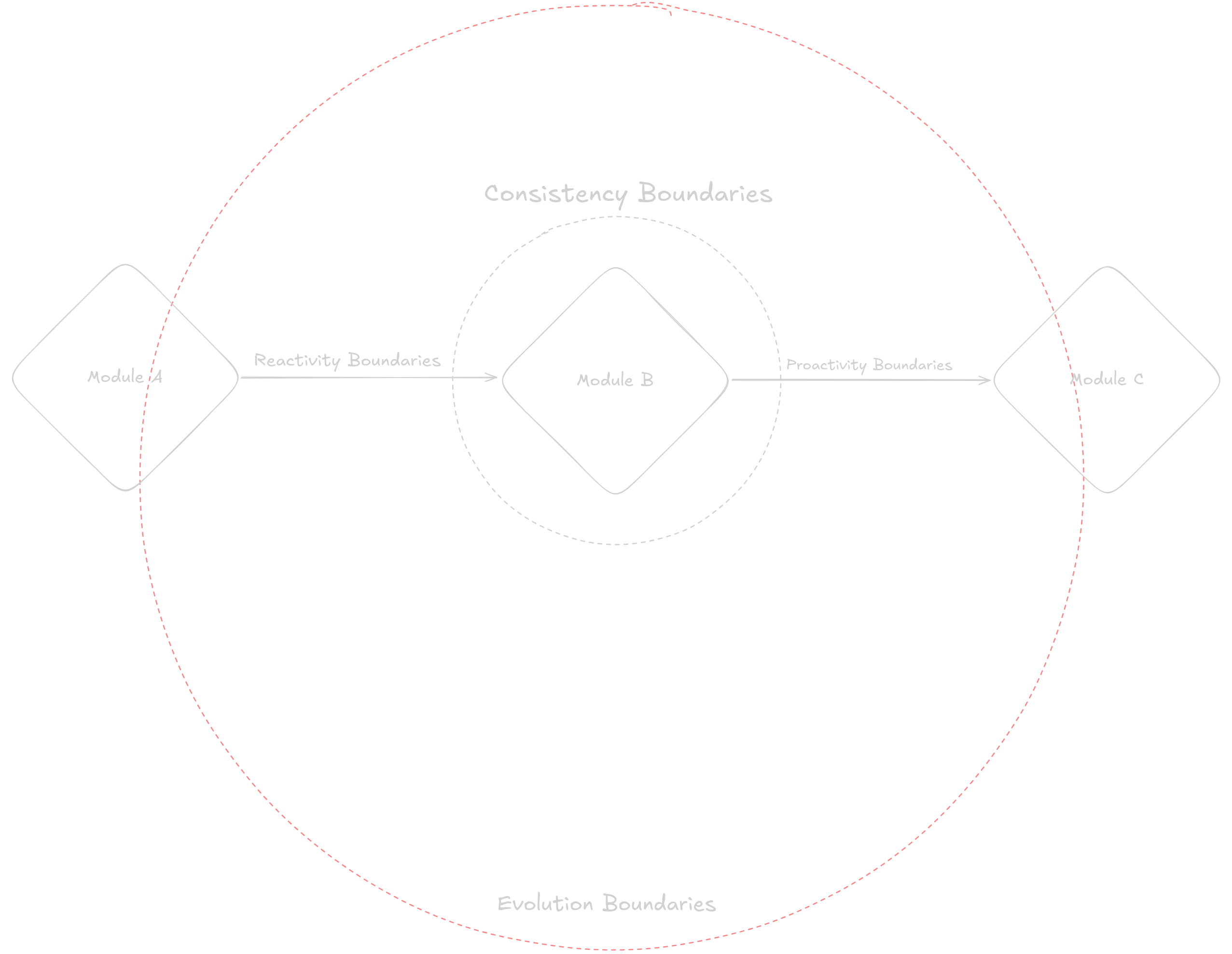
Reactivity Boundaries
Components are not alone in a system: they need to react to changes in other components. The surface between these two components is the reactivity boundary.
Proactivity Boundaries
Components need to command other components to fulfill a business requirement. Usually components will interact through some kind of interface, either being a function call or a method call. The surface of interaction is the proactivity boundaries.
Consistency Boundaries
Data in a component is usually related to data in other components: through deriving new data or by owning the data. The relationship of the components through their data is the consistency boundaries.
Evolution Boundaries
As components interact, in any way, they need also to change. How these components change together is also a property of the system that is relevant for building approachable and scalable software.
Choose properties and tradeoffs
As they can surface useful and expected behaviour.
1. Modules that evolve together benefit of being tighly coupled
Think about having two functions that solve a subset of the same problem. They are likely to be changed together when we are implementing a new feature.
const buildInvoice = lines => {
return {
lines,
total: lines.map((line) => line.total)
.reduce((a, b) => a + b)
}
}
const applyVat = vat => invoice => {
return {
...invoice,
subtotal: invoice.total,
total: invoice.total + (invoice.total * vat)
};
}
const generateInvoice = lines => applyVat(VAT)(buildInvoice(lines))
Simple, tightly coupled modules, when the surface is under control, have the benefit of being extremely easy to change and test. Playing with coupling can provide wonderful benefits into your code base.
2. Modules that do not evolve together should be at most eventually consitent.
It's hard to guarantee consistency when a module changes more frequently than other, as there is a trend for rules to collide and break. Eventual consistency simplifies this by separating data sources and deriving state, instead of sharing state.
3. Reactivity boundaries are as important as Proactivity boundaries
It's common to define contracts on how we proactively interact with other modules. However, when components react to other component changes is extremely complicated and there are few languages that support it out of the box. Leveraging Pub/Sub in Java, Flow in Kotlin, Rx on multiplatform code allows to model these reactivity boundaries in the type system.
An example in Kotlin on using MutableStateFlow:
val clickEvents = MutableStateFlow(emptyList())
val telemetryEvents = MutableStateFlow(emptyList())
clickEvents.collectLatest {
telemetryEvents.tryEmit(TelemetryEvent(CLICK, it))
}
We could use also other operators like map, which in theory, should simplify the code:
val clickEvents = MutableStateFlow(emptyList())
val telemetryEvents = clickEvents.map { TelemetryEvent(CLICK, it) }
However, by doing this, we are shifting the consistency model to causal (there is a linear strong relationship in time) instead of eventual. This increases the coupling, which might be beneficial:
// 1.
val clickEvents = MutableStateFlow(emptyList())
val keyboardEvents = MutableStateFlow(emptyList())
val telemetryEvents = MutableStateFlow(emptyList())
clickEvents.collectLatest {
telemetryEvents.tryEmit(TelemetryEvent(CLICK, it))
}
keyboardEvents.collectLatest {
telemetryEvents.tryEmit(TelemetryEvent(KEYBOARD, it))
}
// 2.
val clickEvents = MutableStateFlow(emptyList())
val keyboardEvents = MutableStateFlow(emptyList())
val telemetryEvents = combine(
clickEvents.map { TelemetryEvent(CLICK, it) },
keyboardEvents.map { TelemetryEvent(KEYBOARD, it) }
)
In the first example, telemetryEvents is decoupled from the source of data, which makes it easier to evolve outside the boundaries of their reactivity boundaries. In the second example, telemetryEvents is a combination of existing flows, which makes impossible evolving telemetryEvents outside of the reactivity boundaries.
And both properties are useful depending on the use case.
4. Module identity is based on their properties and business logic, not code.
This is important when refactoring. When we see two snippets of code that are similar, we tend to merge them into a single function or class so it can be reused. What this actually does is reducing two modules, with their own properties, to one single module.
Before merging code, consider each module properties.
5. Reduce boundaries to the minimum
Avoid fanning-in or fanning-out relationship between modules. If this is necessary, favour eventual consistency, favour reactivity and disregard proactivity: this will make your modules easier to reason about.
So, essentially, be intentional in what properties of your system you want to enforce
This will give you leverage and make your software better for your use case.